DTR Design and Implementation Details
This page documents the requirements and design stages of the new data staging framework which took place around mid-2010.
Issues with previous implementation
Queueing happens per job - that makes it impossible to use potentially more effective processing order
Slow data transfers block those which could be done faster.
Big data transfers block small ones.
Jobs waiting for already cached (or to be cached) files are blocked by other jobs in queue.
Special features of sophisticated protocols are not taken into account - like SRM’s “try later”.
No priorities aka flexible queues.
No support for different credentials for different files.
No bandwidth handling.
No handling of files with different access latency (eg tape vs disk)
No mechanism to choose a preferred replica for the LFC (catalog) inputs, for example: if replicas are in ndgf, swegrid, signet, unige, try with ndgf first.
Task Summary
The initial task was NOT to solve all these issues. The task was to create a framework which could be extended to solve them later, ot to find/adopt such a framework.
Requirements
Effective usage of bandwidth. Whenever any transfer is paused due to any reason (tape stage in, retry later) for estimated time another transfer should use available bandwidth.
Transfer negotiation (with protocols such as SRM) should be independent of physical data transfer.
Each transfer should be capable to use own credentials.
Transfer should be capable of pausing (temporary cancel) and resuming (if protocol allows).
Automatic/dynamic redistribution of bandwidth is needed to allow short transfer to pass through even while big transfers are taking whole bandwidth.
Transfer from multiple alternative locations.
Cache checks should happen independently of data transfer to avoid locks.
Jobs where all files are cached should be processed immediately.
Better description of file source/destination than just URL (options are difficult to handle, something nicer is needed)
Priorities at different levels: among user groups, inside groups. Any other levels? 3 possible levels: among VO, users/roles inside VO, inside user identity.
Ability for users to set relative priority of their own jobs, both before submission and while job is in queue.
Security Requirements
It must be built into the design that no process has higher privileges than necessary
Elevated privileges are required for:
Access to cache. Cache files are only read/writeable by root user so they cannot be modified by jobs
Access to session and control directories. Access to the these directories should be performed under the uid of the job owner. The current method of running as root and chown’ing must not be used.
Elevated privileges are not required for any other parts of the system such as scheduling
Performance Requirements
Must scale higher than current highest workloads
Must be able to handle up to 10000 active jobs (between ACCEPTED and FINISHED)
Must be able to handle up to 1000 active physical transfers whilst ensuring all available bandwidth is used
Must be able to handle transfers which have to wait for several hours before the physical file is ready to transfer
Possible solution to URL options problem
There has been a long standing problem with the format and syntax used to express URLs and associated metadata and options. While not directly related to data staging, it will be addressed as part of the data staging work.
Architecture Proposal
- 3 layers:
Higher layer processing data staging requirements of jobs, collecting requested attributes/properties, resolving priorities (flattening them), managing credentials.
Middle layer schedules individual transfers, suspends and resumes them, distributes bandwidth, etc.
Lower level handles individual transfer protocol, communicates with middle layer to acquire, release and pre-allocate resources (mostly bandwidth), caches connections (if possible).
Any layer can be outsourced to external service, for example gLite FTS
- Basic file staging stages:
Identify transfer options
Check cache
Evaluate authorization (may require bandwidth)
Resolve location (meta-URL, if needed, may require bandwidth)
If needed repeat all steps from beginning
Do transfer
Post-processing (eg register replicas, release cache locks)
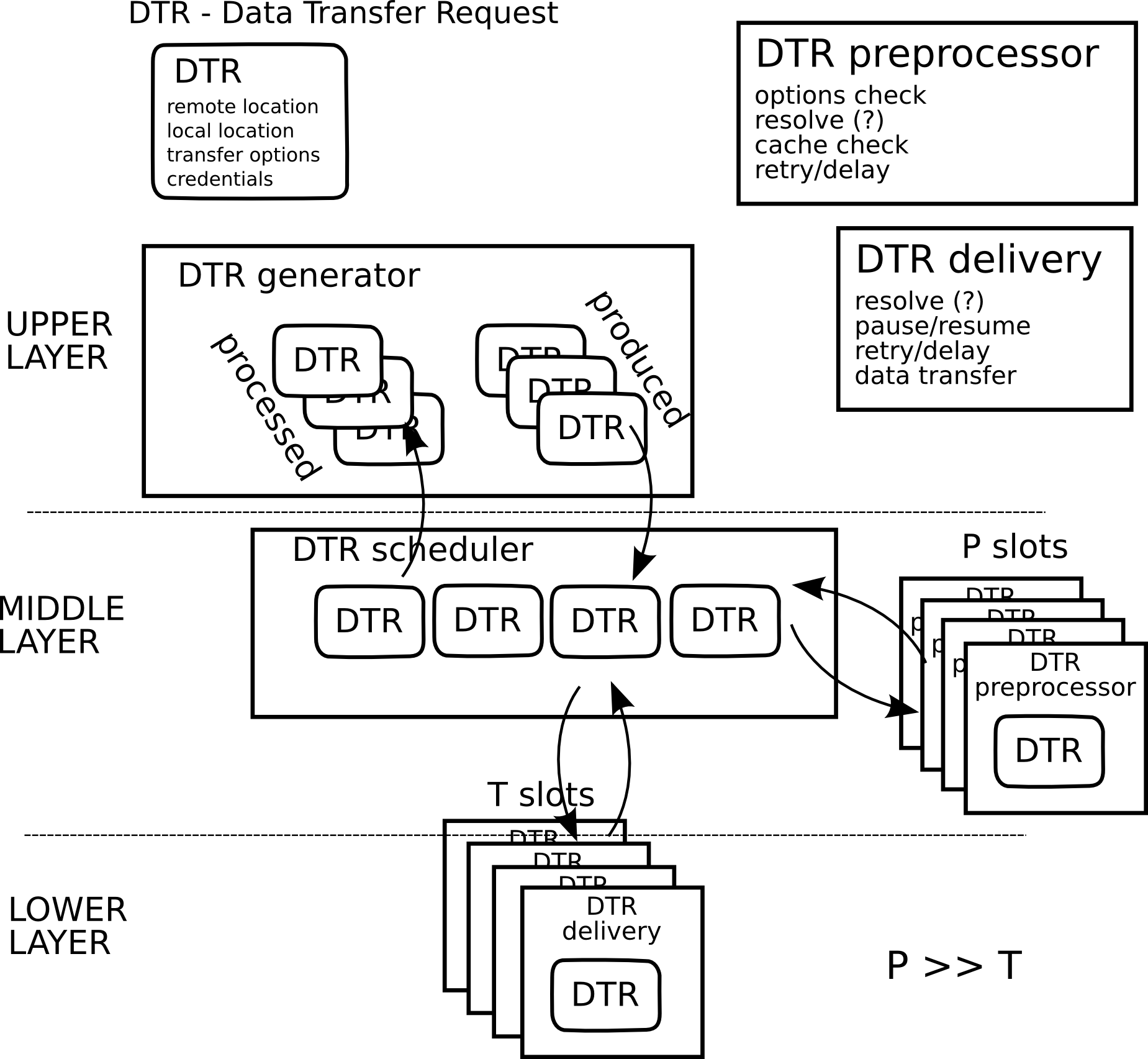
Fig. 12 Functional components and layers.
Requirements for components interfaces (based on protocol descriptions and architecture)
DTR Description
DTR stands for Data Transfer Request. This is the structure that contains several fields that fully describe the file transfer to be performed. One DTR is generated by the generator per each file transfer.
A detailed description and state diagrams of DTRs can be found in the Detailed description of DTRs
DTR Generator to DTR Scheduler
Push DTR from Generator to Scheduler:
DTR contains description of single entity to be transferred - uploaded or downloaded. That includes endpoint, transfer parameters and limits, credentials - possibly multiple, etc.
Multiple DTRs may be affiliated together. Possible reasons and uses:
Belong to same job
Belong to bunch of jobs which user indicated as preferably processed together
Belong to same VO and assigned priorities to be applied within group
Failure of one DTR in group may cancel processing of other DTRs (not sure, may be implemented in Generator)
DTR may have assigned priorities levels. Probably related to groups.
Receive DTR from Scheduler to Generator:
Returned DTR indicates outcome of processing, either positive or negative. In last case it includes description of encountered problems and level of severity.
Cancel DTR in Scheduler
Modify DTR properties in scheduler. Possible usage: - Manipulate priorities
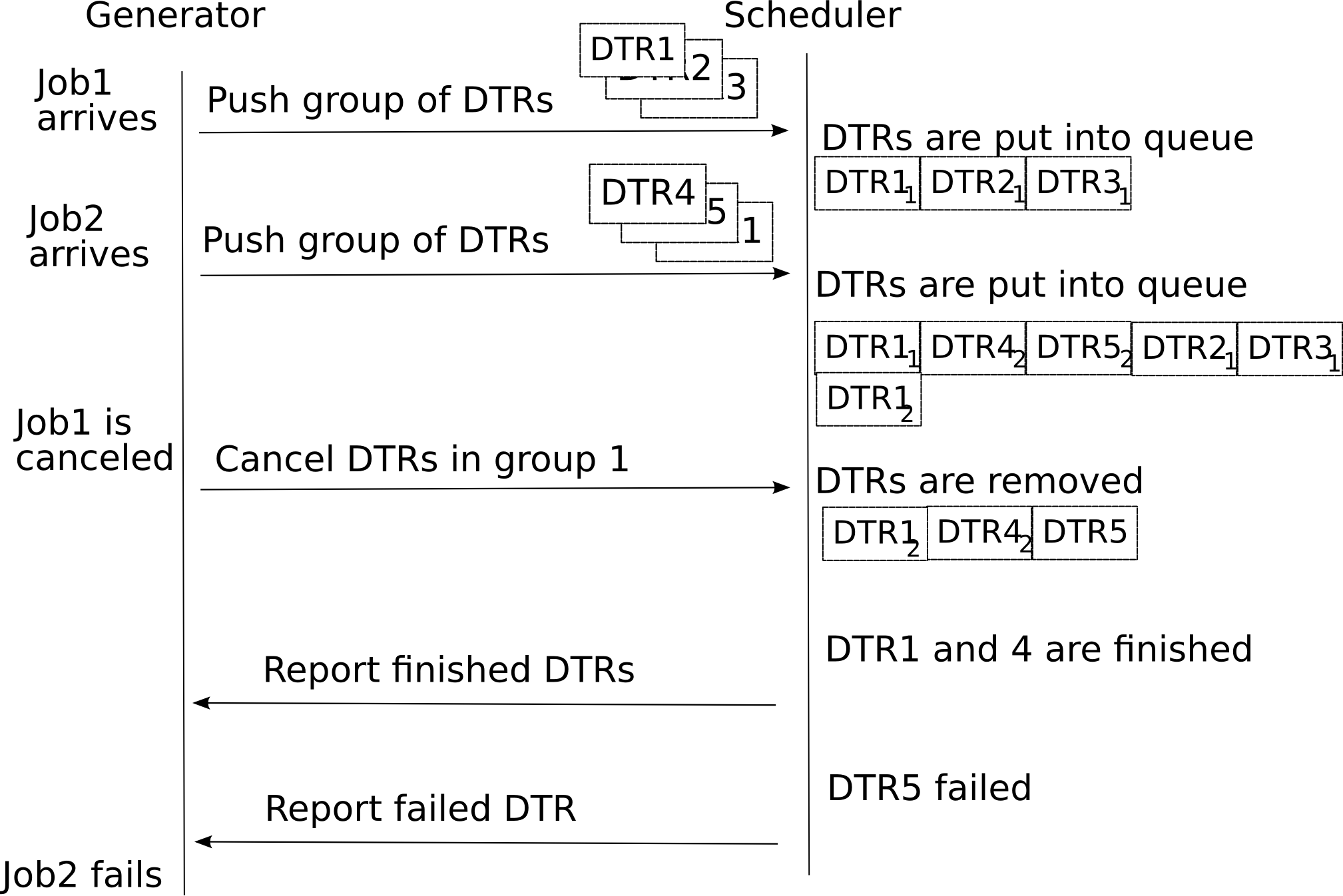
Fig. 13 Example of communication session between DTR Generator and DTR Scheduler.
DTR Scheduler to DTR Preprocessor
Push DTR from Scheduler to Preprocessor
Because DTR preprocessing is supposed to take short time it may include processing timeout
Receive DTR from Preprocessor to Scheduler
Returned DTR indicates outcome of processing
Positive
DTR comes with information need for further processing either in Preprocessor or Delivery unit
DTR may contain multiple/alternative additional endpoints
Probably such DTR may be presented in tree-like diagram
Failure - includes description of encountered problems and level of severity
Delayed processing
Includes retry time and possible margins.
Scheduler must ensure this DTR will go back to Preprocessor within specified time margins.
Cancel DTR in Preprocessor
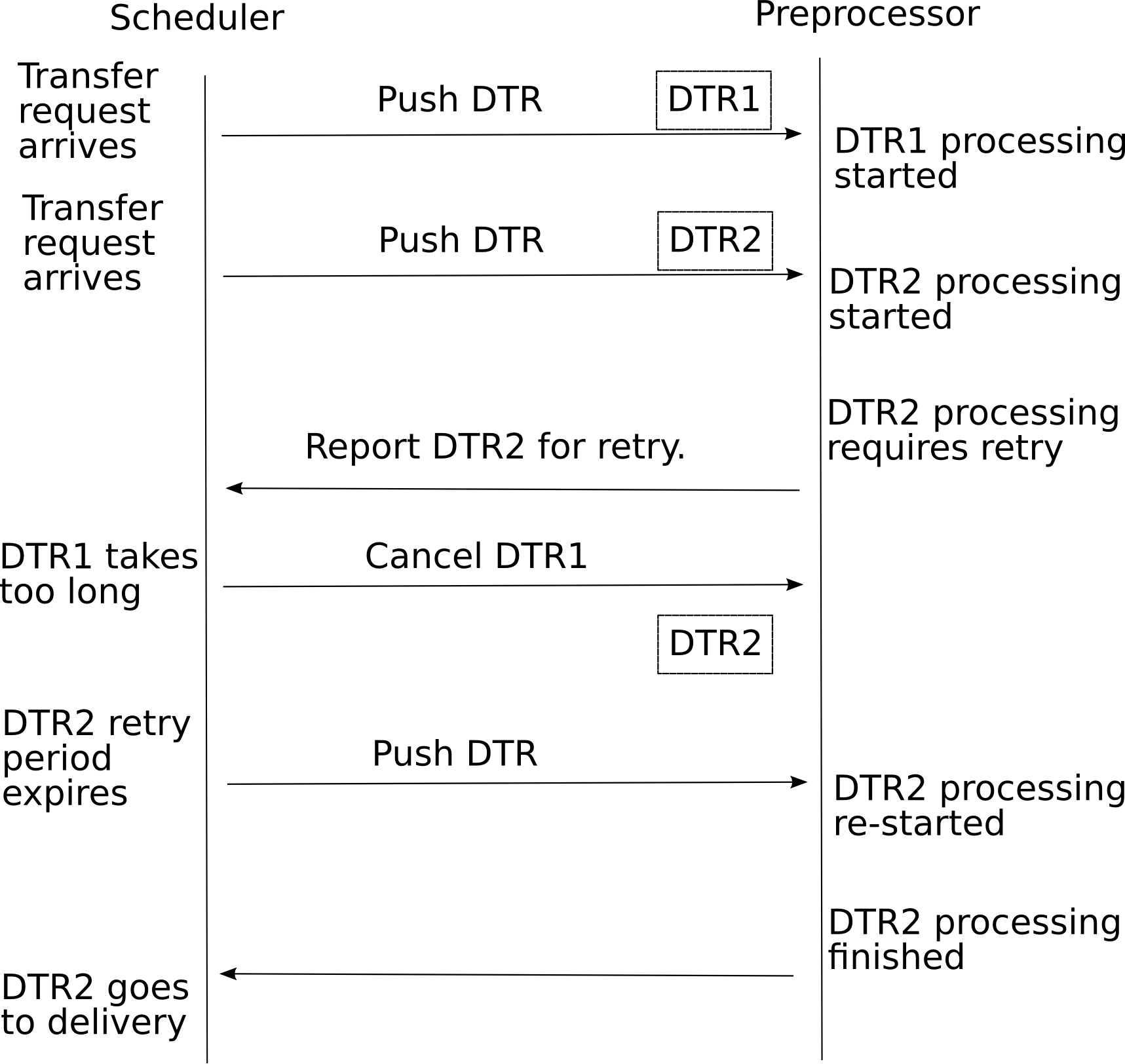
Fig. 14 Example of communication session between DTR Scheduler and DTR preprocessor.
DTR scheduler to DTR delivery
Push DTR from Scheduler to Delivery
DTR may have bandwidth assigned
DTR may have timeout related parameters assigned - minimal transfer rate, maximal inactivity timeout, etc.
Cancel DTR in Delivery
Suspend DTR in Delivery - should DTR leave Delivery or should it stay there?
Receive DTR from Delivery to Scheduler. Returned DTR indicates outcome of processing
Positive
Partially positive (partial data delivered)
Redirection
Failure - includes description of encountered problems and level of severity
Get information about bandwidth currently used by Delivery
Modify assigned bandwidth
May be used to free some bandwidth for urgent transfers

Fig. 15 Example of communiction session between DTR Scheduler and DTR Delivery.
Component Workflows
Generator
The Generator is an integral part of the a-rex process. Internally it performs 4 tasks in following order:
Makes DTRs out of existing job descriptions also assigning priorities and grouping information and makes them available to the Scheduler.
Communicates immediate requests like DTR cancel or suspend to the Scheduler.
Monitors DTR states as reported by the Scheduler (and possibly by other modules) in order to provide feedback to client tools of A-REX asking for job state.
Receives finished/failed DTRs from the Scheduler and initiates job processing continuation. Note: This part may be merged with previous one.
Scheduler
“Queues” are queues of DTRs waiting to enter pre/post-processing or delivery. They are kept internal to the scheduler. The scheduler is the only place with complete knowledge of the system and the only place where priorities are controlled and error conditions are handled. When an event is received and involves sending the DTR to a queue, the DTR is put at a certain position in the queue. Depending on the DTR priority, other DTRs in the queue may be moved, paused or stopped to allow higher priority DTRs to proceed quicker or consume more resources. On receiving an event, the relevant queue is examined and action taken (eg if a delivery finished start a new one).
Reactions to new events
For simplicity error conditions are not included in the workflow here but described separately on the Detailed description of DTRs. They are examined by the scheduler, which will decide the workflow - do any necessary post-processing, decide whether to retry (immediately or after some delay) or to report back to the generator that the DTR definitively failed. DTR state transitions are also described in more detail and with diagrams on the Detailed description of DTRs.
New DTR from generator
if cacheable or meta-protocol:
add to pre-processor queue (for cache check, replica resolution etc)
else if ready to be delivered (base protocol for src and dest):
add to delivery queue
DTR returned from pre-processor
if cached:
send to post-processor to be linked
else if need more pre-processing:
add to pre-processing queue
else:
add to delivery queue
DTR returned from delivery
if post-processing required (index registration, cache linking, release request):
put in post-processor queue
else:
return to generator
DTR returned from post-processor:
Return to generator
DTR cancel notification from generator
if before pre-processing:
return to generator
else if in post-processing:
wait until finished and then send back to clean up
else:
cancel immediately and add to post-processing queue for clean up
DTR modify notification from generator
change request immediately, and modify queue if appropriate
Processor
The processor is divided into two logical parts: the pre-processor and the post-processor. Either part is invoked by the scheduler as a process/thread and has the DTR to process. Therefore, the pre- or post-processor can be a straightforward function, performing the next steps:
The pre-processor:
check endpoint for its presence in cache
if successful, mark DTR as BYPASS_TRANSFER, return the DTR to the scheduler
if file is not in cache, construct cache endpoint for DTR destination and return to scheduler
resolve the replicas of the file, if needed
return the DTR with a failure if no locations have been found
return the list of replicas found to scheduler
Note: The pre-processor doesn’t care if the resolved locations represent meta-protocols themselves, it’s the scheduler’s job to determine it and possibly send this DTR for the pre-processing once again.
query an endpoint
supply information on size, checksum, creation date, access latency as available according to protocol
If an asynchronous request needs to be performed, for example SRM prepareToGet
Start request, mark DTR as STAGING_PREPARING_WAIT, return to the scheduler. An estimated wait time may be set by the pre-processor from information supplied from the remote service.
If a polling request arrives from the scheduler
Check state of asynchronous request and report back to scheduler success, wait more, or error.
If the cancellation request arrives from the scheduler
interrupt the operation, mark the DTR as PREPROCESSING_CANCELLED, return to the scheduler
If the preprocessor hits the timeout during performing these tasks
interrupt the operation, mark the DTR as PREPROCESSING_NOT_FINISHED, return to the scheduler.
Possible features of the pre-processor in the future
for each of resolved locations:
check options one by one (we still have to define transfer options, below is the example), mark in the list to which extent it satisfies the option
can the location provide a required bandwidth
other options, specified for the user
keep processing all the options even if some of them are not satisfied – the scheduler may later review the options and start the processing again
request the file size (if possible) and compute estimated transfer time, mark it in the list for this location
if there are in the list locations that satisfied all the checks
return the DTR as TRANSFER_READY to the scheduler with the list of these locations and their estimated transfer times
if there are no locations in the list that satisfied all the checks
return the DTR with the least severe encountered failure (from most severe to least severe, Location is dead - Location is not authorized - Location doesn’t satisfy the options), so the scheduler can either drop the DTR (in case of dead/non-authorized storages) or review transfer options and try again (in case of unsatisfied options)
The Post-processor:
release stage requests;
register a replica in an index service;
release cache locks;
Delivery
Delivery is a component where the transfer orders are handled. Delivery process is listening to the Scheduler to receive the ready DTRs for transferring or any other events such as decreasing the bandwidth or suspending and canceling the ongoing jobs. Delivery process, reports the status of the DTRs and events to the scheduler periodically.
Transfer request delivery
Pick up a DTR from delivery queue.
Check the source and destination, set the bandwidth, timeout and etc.
Start transferring by placing the received data in a buffer.
Periodically report the status of DTR such as transfered bytes, used bandwidth to Scheduler.
By finishing the data transfer do a checksum
if checksum is correct return a SUCCESS status to the Scheduler
else retry transfer again
High priority transfer request event
Change the DTR to use max bandwidth n
Job suspension
Suspend a transfer request
Keep the transfered data information in the delivery process
Release the used bandwidth
Report the status of suspended DTR to Scheduler
Transferring cancel
Stop transferring
Release the resources if any is in use
Clean up the buffer
Status report to Scheduler
Periodically collect the information of the DTRs in progress.
Calculate used bandwidth, transfered data bytes, status
Report the status to the Scheduler
Protocol Interfaces
Current Interface
The following interface is defined for each protocol through the DataPoint class:
StartReading - Start reading data from the source
StopReading - Stop reading data from the source
StartWriting - Start writing data to destination
StopWriting - Stop writing data to destination
Resolve - Find physical replicas from an indexing service
Check - Verify that the current credentials have access
ListFiles - Find metadata
Remove - Delete
(Pre)Register and (Pre)Unregister - add and delete in indexing service
These do not fulfil all the requirements of the DTR interfaces described above.
New Interface
The main limitation of the current interface is that it does not handle efficiently those protocols such as SRM which involve asynchronous preparation steps. In the new framework, having to wait for a file to be prepared should not block other activities. Therefore the proposal is to split protocols as now into meta and direct protocols, but introduce a third class of stageable protocols and appropriate extra methods to handle them. A stageable protocol could also be a meta protocol or a direct protocol. Extra methods are also needed to handle pausing and cancellation of transfers.
For Meta Protocols (eg LFC, RLS)
Resolve - Resolve replicas in an indexing service
(Pre)Register and (Pre)Unregister - add and delete in indexing service
For Stageable Protocols (eg SRM, Chelonia)
PrepareReading - Prepare the storage service for reading. This may involve preparation of Transport URLs (TURLs) which should then be used for physical data transfer, or operations like reading data from tape to disk. If the protocol’s implementation is asynchronous then this method may return a status that tells the caller to wait and poll later. The caller should call this method again after some period of time (the remote service may provide an estimate of the preparation time).
PrepareWriting - Prepare the storage service for writing. Works similarly to PrepareReading.
FinishReading - Release or abort requests made during PrepareReading, usually called after physical transfer has completed.
FinishWriting - Release or abort requests made during PrepareWriting, usually called after physical transfer has completed.
Suspend - Pause current preparation of transfer
Resume - Resume suspended preparation of transfer (Note: depending on the protocol, suspend and resume may be implemented as stop current request and start new request)
Cancel - Stop preparation of transfer
For Direct Protocols (eg FTP, HTTP)
StartReading - Start reading data from the source
StopReading - Stop reading data from the source
StartWriting - Start writing data to destination
StopWriting - Stop writing data to destination
Modify - Change parameters of transfer such as bandwidth limits
Suspend - Pause current transfer
Resume - Resume suspended transfer
Cancel - Stop current transfer
For All Protocols
Check - Verify that the current credentials have access
List - Find metadata
Remove - Delete
Existing ARC Code
We should aim to re-use as much as possible of the existing ARC code. The arc1 code base will be used for all developments. Code for job description handling and interfacing with the LRMS can remain unchanged, all that concerns us is the code handling the PREPARING and FINISHING states. Job state handling is done in states.cpp. This code can remain largely unchanged but in the ActJobPreparing/Finishing methods the job enters the new system at the upper layer.
The lower level code for data transfer for each protocol is handled in the DMCs. These can largely remain unchanged except for the extra methods in the meta-protocols above.
Caching code can remain unchanged.
PREPARING/FINISHING State Semantics
The semantics of these states may need to be changed - at the moment PREPARING/FINISHING means that the job is transferring data and PENDING those states means a job cannot enter the state due to some limit. In our new system there is less of a distinction between jobs waiting and jobs transferring data, also some files within the job may be transferring while some are waiting. Once the job enters the upper layer of the new system it will be in a staging state even though it may have to wait a long time before any data is transferred.
Processes and Threads
In the current architecture a persistent A-REX thread is spawned by HED. A new data staging process (downloader/uploader) is forked for each job to stage its input or output files. Within each process a thread is created per file. The status of each thread is reported back to the loader process through callbacks and the process exit code tells the A-REX the status of all transfers. There are some problems with this approach:
The A-REX knows nothing about what happens inside the loader until the process exits and cannot communicate with the loader
It is not possible to change the uid of each thread individually so they all run under the uid of the downloader/uploader. The uid of the downloader/uploader depends on configuration. If possible uid of mapped user is used. But if there is cache shared among users that uid will be root or uid of A-REX.
To solve this last problem, processes in the delivery layer writing to or from the session dir must run under the locally mapped uid. Writing to the cache must always be done as root and so cache and non-cache downloads must be done in different processes. This leads to the conclusion that the delivery layer must be separate processes from the scheduling layer. Then to solve the first problem there needs to be a method of communication between the delivery and scheduling layers, which must be two way, so that the scheduler can modify on-going transfers and the transfer can report its status back to the scheduler.
Notes on running processes under mapping uid:
It is only open() operation which needs to be run under special uid. If we follow convention that all open() operations in an executable are called through single wrapper function and put global lock around it, then we can have filesystem access under selected uid inside multi-threaded application. Unfortunately for NFS the process needs to maintain the uid throughout the whole transfer.
This may introduce performance issue if open() operation takes too long, like in case of remote file system.
open() may be called by an external library which we have no control over
according to ‘man open’ “UID mapping is performed by the server upon read and write requests” and hence suggested approach will fail on NFS.
Operations carried out by the pre- and post-processor require access to the filesystem in the following steps
Cache preparation - locking the cache file and checking its existence. This must be done as root.
Cache finalisation - copying or linking the cached file to the session directory. The hard link to the per-job dir must be done as root but the soft linking or copying to the session dir must be done as the mapped user.
Last is rather “must” than “may” to make it work on NFS with root_squash=on. The situation may exist where cache is on NFS and then process copying file must switch uid while accessing file and its copy.
Access to proxy - the proxy is needed when contacting secure remote services. The proxy in the control dir is owned by the mapped user. Therefore either we have to:
Make a copy of the proxy owned by root - this does not fit our security requirements above
Note1: This is how it is done in current implementation. There is no security hole here because this is same proxy which was obtained by A-REX and written to control directory under root uid. So this proxy already belonged to root and making belong to root again makes little difference.
Note2: Because as a rule proxy is stored on local file system it is always accessible by root. Copying of proxy was needed in current implementation due to limitation of Globus libraries - those were able to accept proxy only from file and were checking if proxy belonged to current uid. Because ARC data library allows assigning credentials to communication directly (at least it should, but may be not implemented for some protocols, needs checking) and because proxy is readable by root such trick is not needed anymore.
Use processes rather than threads for the pre- and post-processor, changing the uid of the process to the mapped user
This approach is most probablty not needed for this purpose but may be very much desirable for fighting NFS.
As suggested above, use global open() function to open with mapped id then switch back to root - this suffers the same problems mentioned above
There is no need to do that for proxy because root can always open files belonging to other users
The generator will be a thin layer between the main A-REX process which moves jobs from state to state and the scheduler which processes DTRs - when a job enters the PREPARING or FINISHING state the generator will create DTRs and send them to the scheduler. For the scheduler to be efficient it should run as a separate process (or thread). Each pre-processing step such as resolving replicas in a catalog or a cache permission check should be fast (< few seconds) but should be run asynchronously in order not to block the scheduler if something bad happens.
In summary we have the following processes corresponding to the three layers:
Persistent main A-REX process (thread of HED) and persistent generator thread
Persistent scheduler process (or thread) with temporary threads for pre-processing
Temporary delivery processes created per file transfer
Using processes vs threads should add no more CPU load, however more memory is required. For increasing performance it should be possible to reuse processes in a way similar to how threads are reused.
Implementation Choices
The current system uses files in the control directory for all communication. We may need something more sophisticated for this more complex system, either internal to the new system or also to replace the current files in control dir method. Possibilities:
Files
Sockets
Database
RPC
Libevent - http://en.wikipedia.org/wiki/Libevent
Pipes
Message passing
ActiveMQ - http://activemq.apache.org/
…
Suggestion 1
Use persistent object - file, database record - for storing DTRs. Each object includes:
Description of DTR
Owner of DTR
Last requested action
Current state inside owner (or maybe inside every module).
Each DTR has own ID - may be just file name or record key
Keep simple communication channels between modules - like 2 pipes for example
Whenever DTR is changed its ID is sent over communication channel to module which is supposed to react
As backup modules can scan modification timestamps of objects periodically
Pros:
Simple
Persistency
Cons:
Monitoring of ever changing state - like bandwidth usage - would require constant modification of files/records.
This problem could be solved by providing information which needs no persistency through communication channel. But that would make communication more complex.
Another possible solution is to mmap (should work well with files) objects and flush them to persistent store only if persistent part of information is modified.
Suggestion 2 (used in current implementation)
DTR objects can be rather complicated, so keep them only in memory
In case of process failure all DTRs are reconstructed from control files into initial NEW state
DTRs are passed as objects between threads
Separate threads run for A-REX (including the Generator), Scheduler, and Delivery components
Delivery thread starts new processes for each transfer
These communicate simple status messages (“heartbeats”) through pipes to main delivery thread
Communication between threads through callbacks
Pros:
Simplifies development - no need for complex persistency layer or serialisation code
Fast communication through thread callbacks
Cons:
Having lots of threads increases risks of deadlocks and race conditions
No persistency
No way to communicate from scheduler to transfer processes
If the only communication required is to pause/resume/cancel a transfer it can be done through signals eg SIGSTOP/SIGCONT/SIGTERM
Implementation idea for Suggestion 2
Generator, Scheduler, Delivery processes are singletons and run as persistent threads. The Processor is a singleton.
Note: C++-wise it would be probably more correct to use static methods instead of singletons. With such approach where would be no need to handle singletons outside of class itself hence simplifying interface. Although inside class there may be singleton.
A-REX initiates a request to the data staging system by calling Generator::receiveJob()
Generator creates DTRs and after they finish it modifies the job state directly
A-REX can query job status from Scheduler via Generator
Generator communicates with scheduler by calling Scheduler::receive_dtr method
There is also a Scheduler::cancel_dtrs method which is called by the Generator to cancel DTRs
Scheduler has an instance of DTRList class, which is the storage for all the DTRs in the system.
Scheduler communicates (passes a DTR) to any other process by calling DTR::push() method
Pre-, post-processor and delivery communicate with scheduler by simply changing the status of DTR and changing the owner to “SCHEDULER”. Scheduler will pick up DTRs with changed statuses automatically during next iteration.
When DTR goes from the scheduler to the pre or post-processor, it calls the processDTR() method of the singleton processor within push(). The processor then spawns a thread and returns.
When DTR goes from the scheduler to delivery, within push() it calls the processDTR() method of the singleton delivery. The delivery then spawns a process and returns.
The delivery singleton receives messages through pipes from the transfer processes and reports information in the DTR object.